Jon McLoone, International Business & Strategic Development
A simple question from a six-year-old about hangman turned into another analysis obsession that made me play 15 million games of hangman recently.
Back in 2007, I wrote a game of hangman for a human guesser on the train journey from Oxford to London. I spent the time on the London Underground thinking about optimal strategies for playing it, and wrote the version for the computer doing the guessing on the return journey. It successfully guessed my test words and I was satisfied, so I submitted both to the Wolfram Demonstrations Project. Now, three years later, my daughter is old enough to play, but the Demonstration annoys her, as it can always guess her words. She asked the obvious question that never occurred to me at the time: "What are the hardest words I can choose, so that I can beat it?"
language
English
ignoreaccents
wordlength
showremainingwords
start
guessagain
Gameover-youwin
_
_
_
_
_
bcdegkmoprstw
In case you don't know, the idea of hangman is that one player thinks of a word and tells the other player how many letters it has. The second player repeatedly guesses letters. If a guessed letter is in the word, the word chooser must reveal the position of every occurrence of the letter in the word. If it is not, then the chooser takes great pleasure in drawing a component of a gallows with a man hanging from it. If the gallows and man are complete before the word is fully guessed, the second player has been hanged and loses. There are various designs of gallows and man; I learned on the one above, which has 13 elements, but I have seen many possibilities between 10 and 13, and there are probably others. I'll call these the 10-game and 13-game. My design, the 13-game, is easier for the guesser, as he or she is allowed more mistakes before losing.
Why a hangman? I don’t know. It is claimed that the game dates back to Victorian England, when hanging was probably an acceptable punishment for poor spelling!
Here's how I created these games. First, let me describe the algorithm that we are attacking. My hangman algorithm uses all available information to produce a list of candidate words. At first, the available information is only the length of the word, but later we will know some of the letters and their positions and also some of the letters that are not in the word. All three bits of information can reduce the dictionary very quickly. Next, the game does a frequency analysis of the letters in all of the candidate words (how many of the candidate words contain at least one "a", at least one "b", and so on). Our best chance of avoiding a wrong guess (if we assume that the word has been chosen randomly from the dictionary) is to pick a letter that occurs frequently.
At this point, it is worth introducing the Nash equilibrium from game theory. This is when opposing strategies are found for which neither player can unilaterally improve his or her outcome, even if the opponent's strategy is known. Partly with this in mind, the algorithm doesn't choose the most popular letter, but chooses any one of the possible letters weighted according to the frequency (e.g., if 1,000 candidate words contain "e" and 13 contain "x", then "e" will be picked more than "x" at a ratio of 1000:13.). This is a first iteration toward a Nash equilibrium point; without it, our algorithm is entirely deterministic, so that any word that defeats it will defeat it every time. The opponent would optimize his or her strategy by choosing that word every time. The algorithm also makes the game more fun. My daughter's question can be thought of as the next iteration toward the Nash equilibrium. Knowing the guesser's algorithm, we are asked to optimize the weighting of how we choose words from the dictionary instead of the equal weighting that I had assumed.
(A little digression: I had the pleasure of listening to John Nash, inventor of the Nash equilibrium, Nobel Prize winner, and subject of the film A Beautiful Mind, talk about his Mathematica use at the fifth International Mathematica Symposium in London a few years ago. Every year, there is usually at least one Mathematica user in the Nobel Prize list, though sadly, few Nobel Prize winners are in Hollywood films.)
The easiest way conceptually to answer my daughter's question is with a brute-force Monte Carlo analysis of every possible word. The first thing I did was to re-factor the code from the Demonstration to make it faster. Sifting a 90,000 word dictionary and doing the frequency analysis takes about 0.2 seconds in my Demonstration—instantaneous in an interactive game. But simulating an entire game can require up to 26 such choices, and since I want to simulate 15 million games, I spent a few minutes using the Profiler in Wolfram Workbench to understand where the time goes and was rewarded with a version that was about 10 times faster. This implementation is at the bottom of the post, if you want to repeat or improve on my analysis.
Then I ran it in parallel using gridMathematica. If I had been able to use the Wolfram|Alpha hardware, I would have been done in a few minutes, but I just have a couple of idle office PCs, so I left it to run over the weekend.
I did an initial run of 50 games for each word in the dictionary. Enough to converge to within 10% of the true outcome and enough for a rough ordering. Then I ran further trials on the more promising words, rising to a total of 3,000 games on the shortlist of 1,000 best words. Enough to be pretty certain of their ordering. To save others from having to burn the CPU cycles, I have included the 50 MB of generated data here.
Now that we have this data, we can start analyzing it:
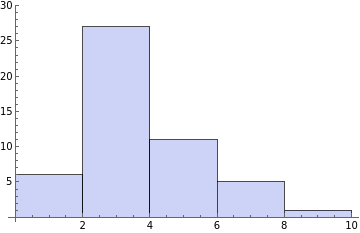
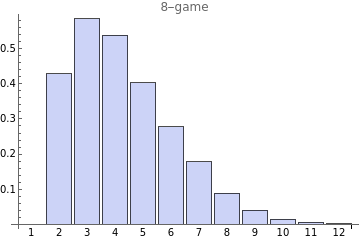
The data shows the number of wrong guesses in each of the 50 games. We can see that the word "difficult" is not very difficult, taking on average 3.3 wrong guesses—not enough to start drawing the man in my design. Out of 50 games, the algorithm never fails on a 10-game or even comes close to losing a 13-game. Though if it had played an 8-game, it would have lost once.
In[4]:=
Histogram[SimulationData["difficult"]]
Out[4]=
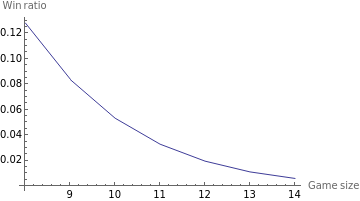
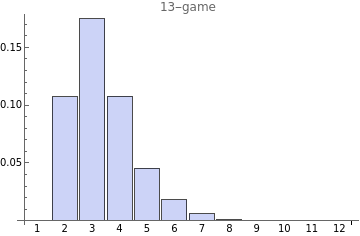
Let's look at the overall performance of the algorithm on a word chosen randomly from the dictionary (the original assumption). We can't look at average miss rates, since a game with 13 wrong guesses is equally a loser in a 13-game as a game with 20 wrong guesses. What we care about are win ratios, and those depend on the game size.
If the algorithm didn't use frequency analysis at all, then the win ratios would be 10% for the 13-game and 25% for the 10-game (as a careless coding error taught me in the first run of the experiment).
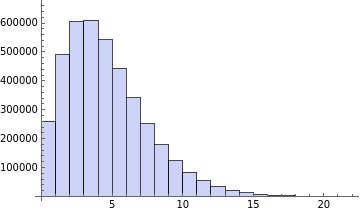
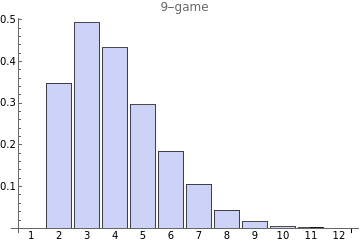
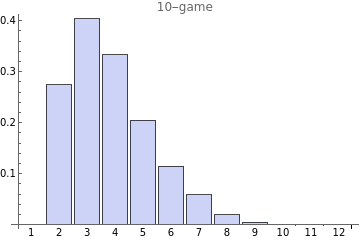
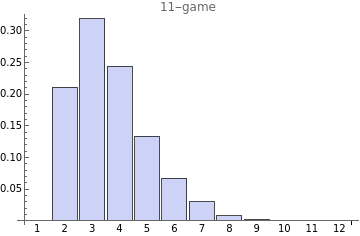
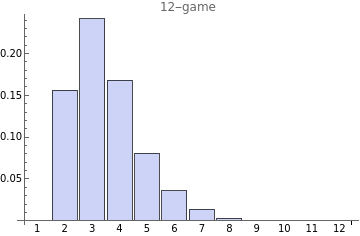
Here is the distribution of game outcomes. Half of the time it makes 4 or fewer wrong guesses.
Which are better, long words or short? When I played my daughter, I used short words, as I had assumed they were easier (they are certainly easier for her to spell), but I was surprised to discover that the average mistake rate is highest for short words. The reason seems to be simply that the more the letters vary, the less likely a person is to miss them. In the extreme, a word with 14 different letters cannot win a 13-game. There are only 12 wrong letters out there.
So if we only remember one rule, it is to use 3-letter words. And the more pieces in the gallows' design, the more this is the case. But we are interested in the very best words, so here is the score for the best word of each word length:
With careful choice, the very best words of each word length are more evenly matched.
And interestingly, if we sort the words by win ratio, the very best words have dramatically better scores than those only a few places back down in the rankings. Each line here is a different game size from 9 to 13. The jaggedness in the lower ranking words is due to insufficient simulation data and not a real phenomenon in the algorithm.
OK, enough about the trends, here are the best words:
As you might expect, low frequency letters like "x" and "z" are a big factor, but letter repetitions are also useful, since they make longer words have a similar number of different letters as shorter words.
So there we have it: "jazz" wins most for all game sizes. Though we can see odd variance by game size. "Jazzed" does progressively worse as the game size goes up, but "faffed" does progressively better. Understanding that is another project!
We can now improve our word selection algorithm. Instead of choosing a word randomly, we should weight our choice toward words with high win ratios.
Of course, this is only one more step toward the Nash equilibrium point. If the guesser updates the algorithm to take into account that strategy, we will have to repeat this entire experiment, to get an even better strategy. Eventually the two algorithms would likely converge on a point where every word has the same win ratio, and we will know the optimal game outcome. I suspect that the 13-game is essentially solvable. There are enough words that are easily guessed that taking more risks with those, to test the harder words, will improve the guessing algorithm from a 99% success rate to 100%. At that point, we are at equilibrium—in the words of WOPR, "A strange game. The only winning move is not to play." (The WarGames reference is particularly relevant, since the Nash equilibrium was used as the theoretical basis for the Cold War nuclear strategy of mutually assured destruction, and the climax of the film was essentially this kind of simulation—with added computer self-awareness.)
For the 10-game, I learned only enough to see that the ultimate algorithm may be quite complicated and that there is more richness in this simple game than I had expected.
If you are more intent on fun, then pick the best of the long words. Here is a table of the best words of each length for the 10-game. They don't do as well as the 3–5 letter words, but you can't beat "powwowing", "bowwowing", and "huzzahing" for entertainment!
This is all based on the 90,000 word English dictionary built into Mathematica. Results may be very different for larger dictionaries or other languages.
Implementation notes
First, I simplify the dictionary. In my version of the game accents are ignored. There are strictly 26 letters. In other languages, this may not be a valid choice.
Remove any words with apostrophes or hyphens and with uppercase letters (proper names, acronyms, etc). Manually add back in the word "I" that gets removed by this process. This produces a dictionary of a little over 90,000 words.
Create subdictionaries for each word length.
Pick a word from a candidate set according to the weights from the frequency analysis.
Now simulate one or more entire games.
Now we parallelize. Launch some remote machines and share the program. If you don't have a multicore computer or several computers, then just use the SimulateGame function directly.
Now give a simulation run for one word to each of the kernels. Append the results to local files as we get them, so that we can interrupt, without loss of data. Repeat over the whole dictionary.
My initial run was 50 games per word for the whole dictionary. Rerunning this code for parts of the dictionary appends the results to the previous simulations.
When finished, put all the separate files together ready for analysis.